
Enterprise businesses face a distinct SEO challenge. Their websites often house thousands of pages and diverse elements such as expansive product catalogs, sophisticated ecommerce functionalities, and even sprawling networks of franchise locations.
Large enterprise websites have a great chance to rank high in search results, but making this happen depends on correctly using technical SEO within the website’s structure.
While a fantastic content strategy can lead to rapid growth, it can only take you so far if your website’s technical foundation is unstable. Technical SEO pushes your content to the top of search engine results.
Today, we’ll dive deep into the unseen elements that might be eluding your enterprise SEO audit. Get ready to uncover the hidden gems that could supercharge your organization’s SEO game.
A comprehensive enterprise SEO audit
When conducting an enterprise-level SEO audit, it’s important to remember that technical SEO is just one part of the larger picture. A holistic audit strategy encompasses:
- Technical SEO audit: Uncover and address critical technical issues that underpin your website’s overall SEO health.
- Content audit: Evaluate your website content’s quality, relevance, and effectiveness. Identify opportunities for improvement and gaps for new content.
- Keyword audit: Understand how your target audience searches for your products or services and how that aligns with your website’s content strategy.
- Backlink audit: Examine the quality and relevance of websites linking to yours.
- Competitive analysis: Analyze your competitors’ SEO strategies to gain insights and differentiate your approach.
- Local SEO audit (if applicable): For businesses with physical locations or franchises, assessing local search performance is vital.
- User experience audit: Evaluate the overall usability and accessibility of your website.
While this article focuses primarily on the technical SEO audit, it’s important to recognize that all these audits work collaboratively to shape a holistic enterprise SEO strategy. Focusing solely on technical SEO is a gap in itself.
Uncovering hidden gaps in your enterprise SEO audit
Think of SEO as building a skyscraper. Technical SEO is the foundation that upholds your website’s search engine results. A foundation that is not strong can quickly topple in the SERPs. The technical backbone is even more essential at the enterprise level.
Two challenges create gaps in enterprise SEO audits:
- The large size of enterprise websites can make common areas of your technical audit much more complex.
- There are elements unique to enterprise organizations that can be overlooked in a basic audit.
This article goes beyond the standard on-page audit elements (like titles, descriptions and header tags) to examine potential gaps in your enterprise technical SEO audit stemming from the complex nature of these websites. We’ll explore:
- Canonicalization issues that can lead to significant duplicate content penalties.
- Indexing issues that span across internal linking, sitemaps, and URL structure.
- How to approach organizational challenges with prioritization.
Correct canonical implementation
Canonical tags guide search engines to the preferred version of a webpage when duplicate or similar content exists.
In enterprise setups, such as franchise websites with numerous locations and sprawling ecommerce platforms, the correct implementation of canonical tags becomes paramount.
When a page contains unique content, its canonical tag should be self-referencing.
<link rel=”canonical” href=”https://www.examplesite.com/unique-page/”>
However, within the intricate landscapes of enterprise websites, it’s commonplace to encounter content duplication across numerous pages.
In such cases, the purpose of canonical tags shifts to acknowledging the original source of the content or the page you intend to rank.
This is especially critical when dealing with sprawling product catalogs, franchise websites and other setups where many pages may contain duplicate content.

Common canonical tag mistakes
Let’s dissect common canonical tag pitfalls within each category:
- Generic.
- Ecommerce.
- Franchise websites.
Generic canonical tag issues
- Non-usage of canonical tags: Failing to employ canonical tags at all is a cardinal error, as it leaves search engines without guidance.
- Self-referencing tags for duplicate content: another prevalent mistake is the overuse of self-referencing canonical tags on pages that should reference the authoritative source of duplicate content.
- Canonical chains: Complex canonical chains, where one page references another, which, in turn, references yet another page, can befuddle search engines. For example, Page A canonicalizes to Page B, which canonicalizes to Page C.
Ecommerce canonical tag issues
- Product pages: Product pages that contain unique options/content reference a parent product page. This leads to the deindexing of unique product pages that should be in Google’s index. However, if the product pages all contain the same content, a canonical tag referencing a single version or parent can be used.
- Product category pages: Product catalogs that use faceted navigation for product category or listing pages should have a canonical tag that references the main parent category. This helps ensure the Google crawl budget is focused on the top pages.
Franchise canonical tag issues
The URL structure for franchise websites can vary widely for displaying national and local content, introducing severe content duplication issues.
Consider a national blog syndicated across all local franchise websites, causing a network of duplicate content. All sub-site pages must contain a canonical tag citing the original national source of the content.

Finding canonical errors in Google Search Console
Google Search Console Page Indexing report can help flag potential indexing issues created by improper canonical tag use. These flags include:
- Duplicate without user-selected canonical: When Google finds two or more pages with duplicate content, but neither page has a canonical tag pointing to the other.
- Duplicate, Google selects a different canonical than the user: When Google finds two or more pages with duplicate content, then chooses a different canonical page than the one you specified. This is an important flag to review, as Google may not choose the correct page. This will require you to take action to correct it.
- Alternate page with proper canonical tag: When Google finds a page with a canonical tag, but the target URL is not a valid page. These should be addressed quickly by updating the canonical tag.
- Mismatched canonical tags: When Google finds pages with duplicate content but the canonical tags point to different target URLs.
- Incorrect canonical elements: Google’s flag for incorrectly formatted canonical tags.
The pitfall of neglected canonical tags
Another common misstep with Enterprise SEO is the “set it and forget it” approach to canonical tags.
While canonical tags can serve as guiding beacons for your expansive website, their incorrect application can pave the way for substantial ranking challenges and even deindexing.
Continue to monitor your canonical tags regularly to safeguard your SEO endeavors.
Indexing for enterprise websites
Indexing and crawlability are the cornerstones of enterprise SEO. With thousands or even millions of pages, ensuring the right pages are being indexed is key.
But, given the size of these sites, tackling the indexing audit can be a beast, and essential pieces may be missed.
Efficient indexing deep dives
Google Search Console offers a wealth of information about indexing, including data on indexed pages, excluded pages, and crawl errors. This data can be invaluable in identifying issues with indexing.
However, relying on Google Search Console alone only gives you one piece of the puzzle.
Begin your audit by running a Screaming Frog crawl of your website. This crawl will comprehensively list every page’s response codes, sitemap presence, no-index tags, broken links, and other critical data points.
Comparing this data with Google Search Console’s Page Indexing report can aid you in identifying potential indexing issues like those outlined below.

Orphaned pages
An orphan page is webpage that is not linked to any other page. This predicament often arises when pages are included in your sitemap but lack any meaningful on-page link structure or navigational pathways.
With Google's ranking algorithm increasingly valuing internal linking, a thoughtful internal link structure is paramount for all ranking pages.
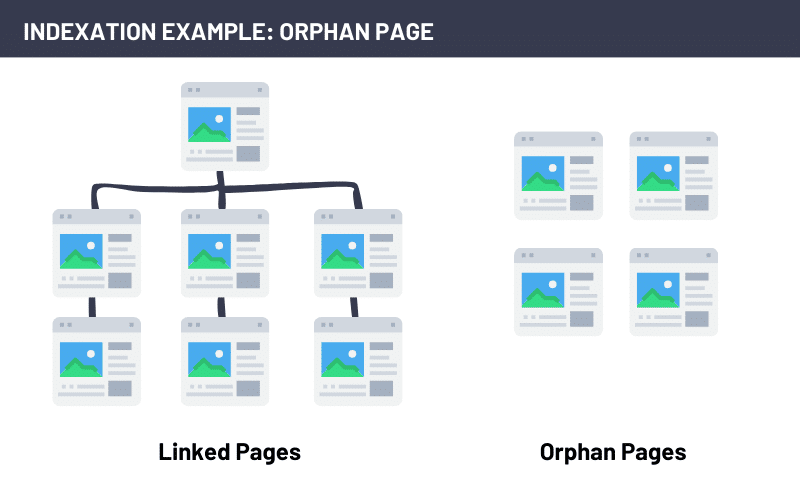
Orphaned pages are easy to spot in a Screaming Frog crawl. After completing your crawl and running the crawl analysis, Screaming Frog compiles a list of your orphan URLs.
When confronted with an orphaned page, evaluate its purpose and role in your website's ecosystem:
- Relevance: Determine whether the orphaned page should be part of your website's indexing. If it holds no relevance or value, consider removing it or making it not indexable.
- Internal linking: If the page possesses merit and should be included in your website's index, build internal link pathways to the page by establishing connections from relevant pages.
XML sitemap and robots.txt files
Imagine a large and intricate library with no central repository listing all the books within. Finding what you are looking for would be madness. Or worse yet, a repository missing some books while listing others that weren’t even there. That is your enterprise website without an XML sitemap.
The XML sitemap helps search engines navigate that labyrinth of your site. The robots.txt file helps search engines find the roadmap.
Using Google Search Console’s Page Indexing report is the quickest way to identify errors in your sitemap.xml or robots.txt files that could impact indexing.
Specifically, look for any errors with accessing the sitemap.xml and robots.txt files. Then, look for any submitted pages blocked by the robots.txt file.
The indexing deep dive: Crawl vs. sitemap vs. index
Elevate your sitemap review to a more comprehensive level by meticulously comparing a complete Screaming Frog crawl and Google's index. The primary objective here is to unearth any indexing disparities that may exist.
For the Screaming Frog crawl, export the complete HTML page list, paying particular attention to the following attributes for each page:
- Status: Ascertain the status of each page, identifying if they are accessible or encounter any issues during crawling.
- Indexability: Determine whether each page is marked as indexable or carries any restrictions.
- Canonical link element: Review the canonical link elements to ensure they correctly point to the preferred versions of each page.
- Sitemaps: Extract a comprehensive list of all URLs featured in the sitemap directly from the "Sitemaps" tab within Screaming Frog.
In Google Search Console, access the list of all indexed pages by navigating to the Pages Indexing report and selecting "View data about indexed pages," as indicated below.

Now comes the critical step: Compare your compiled list of pages indexed by Google with the data obtained from your Screaming Frog crawl.
This side-by-side analysis will unveil any disparities in indexing, allowing you to pinpoint the exact pages where gaps in indexing may exist.
URL issues that can hinder indexing
Within indexing challenges, URL issues can be pivotal in determining how search engines perceive and rank your webpages. These seemingly minor discrepancies can significantly impact the overall health of your website's indexing.
Let's delve into three URL-related issues that may be missing from your audit but can inhibit proper indexing.
Missing HTTP to HTTPS redirect
Ensuring a secure connection to your website is paramount. It doesn’t stop there. All HTTP (or non-secure) versions of your webpages or resources should redirect to the proper HTTPS version.
With HTTPS as a ranking factor, correct implementation and the presence of the HTTP redirect are essential. Incorrect implementation can also lead to duplicate content, as Google sees two versions of every webpage.
Use your .htaccess file to bulk rewrite http to https. An example is shown below.
RewriteEngine On
RewriteCond %{SERVER_PORT} 80
RewriteRule ^(.*)$ https://%{HTTP_HOST}%{REQUEST_URI} [R=301,L]Loading both WWW and non-WWW as unique pages
The decision to use "www" or omit it from your website's URL can inadvertently create content duplication and indexing complications. When both versions of your site's URL are accessible, it can confuse search engines and lead to suboptimal rankings.
It’s important to identify the preferred version of your website’s URL. Then redirect the non-preferred version.
Here is an example code to implement in your .htaccess for redirecting non-www to www:
RewriteEngine On
RewriteCond %{HTTP_HOST} !^www\. [NC]
RewriteRule ^(.*)$ http://www.%{HTTP_HOST}/$1 [R=301,L]Mixed case URLs
URLs are typically case-insensitive, meaning that capitalization variations should resolve to the same content. However, some servers may interpret uppercase and lowercase letters differently.
This can result in indexing challenges, particularly if inconsistent URL capitalization is used across your site.
Mixed case issues can be resolved with the following code added to the .htaccess file:
RewriteEngine On
RewriteCond %{REQUEST_URI} ^/(.*)$ [NC]
RewriteRule ^/(.*)$ /$1 [R=301Crafting an actionable enterprise SEO plan
One of the biggest gaps in enterprise SEO audits is often what comes next.
Your audit will likely reveal a sizable amount of issues, the resolutions of which have varying levels of effort and impact.
Translating your findings into a clear and actionable plan with the maximum impact in mind is crucial.
Set expectations
Don’t get overwhelmed when your audit reveals 5 million individual errors. Remember that it’s all about opportunity cost.
Your goal isn’t to have a site with zero warnings or errors. Your goal is to continually improve your site’s overall SEO health.
Focus on high-priority items
With your expectations in line, focus on your high-impact and low-effort items first.
Your high-impact items are those that will have the greatest positive impact or those that will alleviate existing negative impacts. These include the gaps outlined above related to indexing and canonicalization.
Low-effort items, or low-hanging fruits, are technical items of varying impact levels that are relatively easy to implement. For example, if we find any URL Issues (like the http redirect), these can be solved by simply updating the .htaccess file.
This is a great example of a recommendation with both high impact and low effort. Start with these and continue to prioritize your remaining recommendations from here.
Avoid overemphasizing low-priority flags
While it's essential to be thorough in your audit, avoid overemphasizing low-priority flags that may not significantly impact your website's performance. This includes warnings that don’t have a significant impact on SEO.
For example, your schema validator may flag a warning that the pricing variable is missing in your product schema. If price is not a data point you have available, remember many of these warnings are optional. Having some information is better than nothing.
Assessing tech debt and organizational challenges
Every enterprise operates within its unique ecosystem, with its own technical and organizational challenges. Assess your tech debt and understand what can and can’t be done within your website infrastructure.
Incorporate in your action plan what items you can address and what items may require further development.
Bridging the gaps for SEO excellence
In this article, we've explored the unique challenges expansive enterprise websites face in achieving digital success.
From canonicalization to indexing, we've highlighted several hidden gaps in your technical audits that can hinder enterprise SEO success.
By bridging these gaps and emphasizing actionable plans, priorities, and continuous monitoring, we've paved the way for mastering enterprise SEO.
The post What your enterprise SEO audit may be missing appeared first on Search Engine Land.
via Search Engine Land https://ift.tt/vFQj7VT
No comments:
Post a Comment