
My team and I have written over 100 production-ready AI prompts. Our criteria are strict: it must prove reliable across various applications and consistently deliver the correct outputs.
This is no easy endeavor.
Sometimes, a prompt can work in nine cases but fail in the 10th.
As a result, creating these prompts involved significant research and lots of trial and error.
Below are some tried-and-true prompt engineering strategies we’ve uncovered to help you build your own prompts. I’ll also dig into the reasoning behind each approach so you can use them to solve your specific challenges.
Getting the settings right before you write your first prompt
Navigating the world of large language models (LLMs) can be a bit like being an orchestra conductor. The prompts you write – or the input sequences – are like the sheet music guiding the performance. But there’s more to it.
As conductors, you also have some knobs to turn and sliders to adjust, specifically settings like Temperature and Top P. They’re powerful parameters that can dramatically change the output of your AI ensemble.
Think of them as your way to dial up the creativity or rein it in, all happening at a critical stage – the softmax layer.
At this layer, your choices come to life, shaping which words the AI picks and how it strings them together.
Here’s how these settings can transform the AI’s output and why getting a handle on them is a game-changer for anyone looking to master the art of AI-driven content creation.
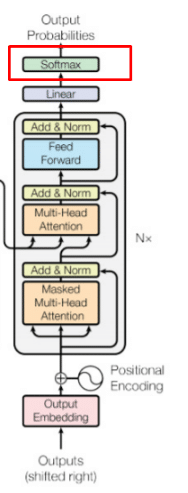
To ensure you’re well-equipped with the essential information to grasp the softmax layer, let’s take a quick journey through the stages of a transformer, starting from our initial input prompt and culminating in the output at the softmax layer.
Imagine we have the following prompt that we pass into GPT: “The most important SEO factor is…”
- Step 1: Tokenization
- The model converts each word into a numerical token. For example, “The” might be token 1, “most” token 2098, “important” token 4322, “SEO” token 4, “factor” token 697, and “is” token 6.
- Remember, LLM’s (large language models) deal with number representations of words and not words themselves.
- Step 2: Word embeddings (a.k.a., vectors)
- Each token is transformed into a word embedding. These embeddings are multi-dimensional vectors that encapsulate the meaning of each word and its linguistic relationships.
- Vectors sound more complicated than they are, but imagine we could represent a really simple word with three dimensions, such as [1, 9, 8]. Each number represents a relationship or feature. In GPT models, there are often 5,000 or more numbers representing each word.
- Step 3: Attention mechanism
- Using the embeddings of each word, a lot of math is done to compare the words to each other and understand their relationships to each other. The model employs attentional weights to evaluate the context and relationships between words. In our sentence, it understands the contextual importance of words like “important” and “SEO,” and how they relate to the concept of an “SEO factor.”
- Step 4: Generation of potential next words
- Considering the full context of the input (“The most important SEO factor is…”), the model generates a list of contextually appropriate potential next words. These might include words like “content,” “backlinks,” “user experience,” reflecting common SEO factors. There are often huge lists of words, but they have varying degrees of likelihood that they would follow the previous word.
- Step 5: Softmax stage
- Here, we can adjust the output by changing the settings.
- The softmax function is then applied to these potential next words to calculate their probabilities. For instance, it might assign a 40% probability to “content,” 30% to “backlinks,” and 20% to “user experience.”
- This probability distribution is based on the model’s training and understanding of common SEO factors following the given prompt.
- Step 6: Selection of the next word
- The model then selects the next word based on these probabilities, making sure that the choice is relevant and contextually appropriate. For example, if “content” has the highest probability, it might be chosen as the continuation of the sentence.
Ultimately, the model outputs “The most important SEO factor is content.”
This way, the entire process – from tokenization through the softmax stage – ensures that the model’s response is coherent and contextually relevant to the input prompt.
With this foundation in place – understanding how AI generates a vast array of potential words, each assigned with specific probabilities – we can now pivot to a crucial aspect: manipulating these hidden lists by adjusting the dials, Temperature and Top P.
First, imagine the LLM has generated the following probabilities for the next word in the sentence “The most important SEO factor is…”:
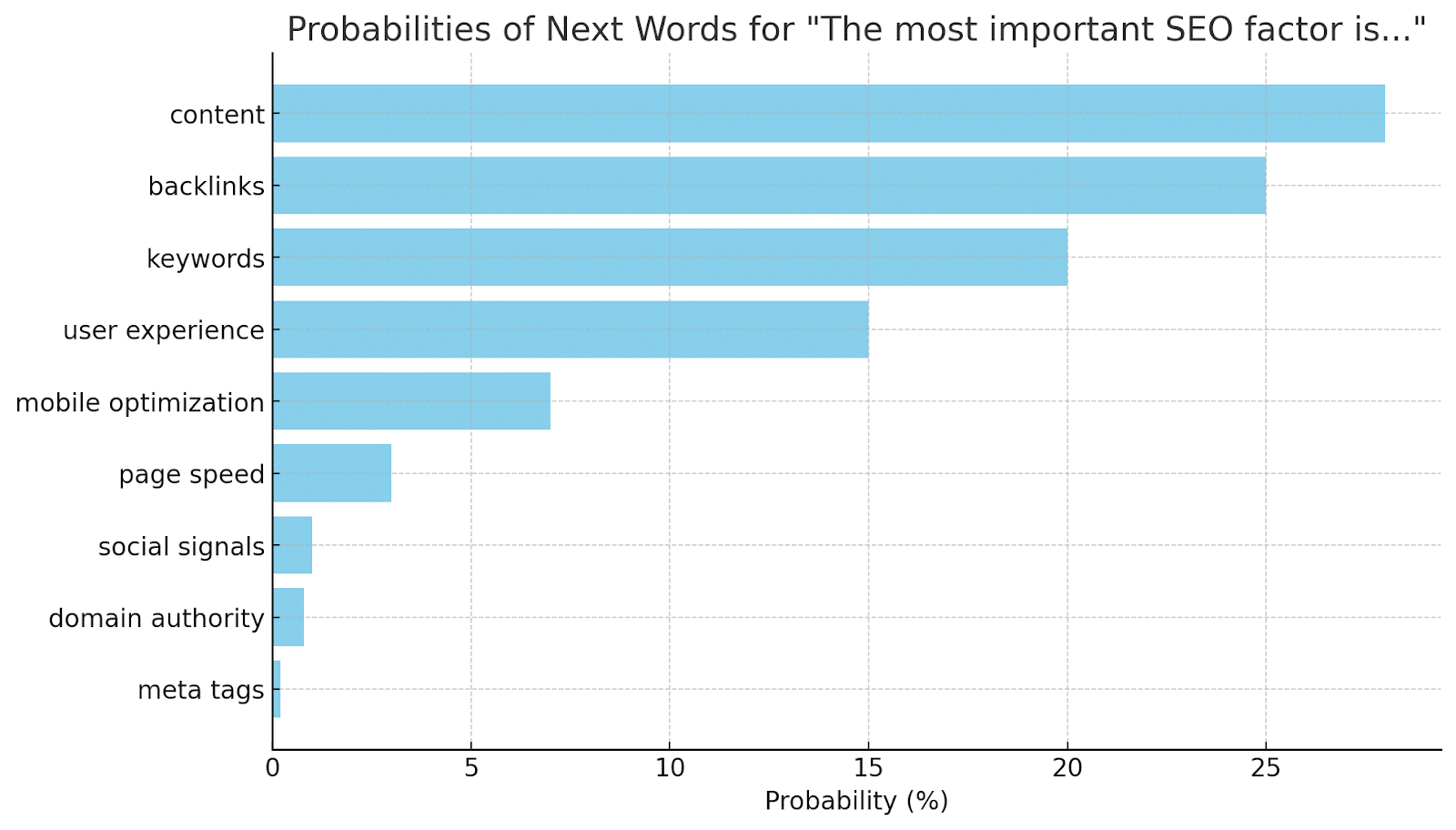
Adjustable settings: Temperature and Top P

Impact of adjusting Temperature
The best way to understand these is to see how the selection of possible words might be affected by adjusting these settings from one extreme (1) to (0).
Let’s take our sentence from above and review what would happen as we adjust these settings behind the scenes.
- High Temperature (e.g., 0.9):
- This setting creates a more even distribution of probabilities, making less probable words more likely to be chosen. The adjusted probabilities might look like this:
- “content” – 20%
- “backlinks” – 18%
- “keywords” – 16%
- “user experience” – 14%
- “mobile optimization” – 12%
- “page speed” – 10%
- “social signals” – 8%
- “domain authority” – 6%
- “meta tags” – 6%
- The output becomes more varied and creative with this setting.
- This setting creates a more even distribution of probabilities, making less probable words more likely to be chosen. The adjusted probabilities might look like this:
Note: With a broader selection of potential words, there’s an increased chance that the AI might veer off course.
Picture this: if the AI selects “meta tags” from its vast pool of options, it could potentially spin an entire article around why “meta tags” are the most important SEO factor. While this stance isn’t commonly accepted among SEO experts, the article might appear convincing to an outsider.
This illustrates a key risk: with too wide a selection, the AI could create content that, while unique, might not align with established expertise, leading to outputs that are more creative but potentially less accurate or relevant to the field.
This highlights the delicate balance needed in managing the AI’s word selection process to ensure the content remains both innovative and authoritative.
- Low Temperature (e.g., 0.3):
- Here, the model favors the most probable words, leading to a more conservative output. The probabilities might adjust to:
- “content” – 40%
- “backlinks” – 35%
- “keywords” – 20%
- “user experience” – 4%
- Others – 1% combined
- This results in predictable and focused outputs.
- Here, the model favors the most probable words, leading to a more conservative output. The probabilities might adjust to:
Impact of adjusting Top P
- High Top P (e.g., 0.9):
- The model considers a wider range of words, up to a cumulative probability of 90%. It might include words up to “page speed” but exclude the less probable ones.
- This maintains output diversity while excluding extremely unlikely options.
- Low Top P (e.g., 0.5):
- The model focuses on the top words until their combined probability reaches 50%, possibly considering only “content,” “backlinks,” and “keywords.”
- This creates a more focused and less varied output.
Application in SEO contexts
So let’s discuss some of the applications of these settings:
- For diverse and creative content: A higher Temperature can be set to explore unconventional SEO factors.
- Mainstream SEO strategies: Lower Temperature and Top P are suitable for focusing on established factors like “content” and “backlinks.”
- Balanced approach: Moderate settings offer a mix of common and a few unconventional factors, ideal for general SEO articles.
By understanding and adjusting these settings, SEOs can tailor the LLM’s output to align with various content objectives, from detailed technical discussions to broader, creative brainstorming in SEO strategy development.
Broader recommendations
- For technical writing: Consider a lower Temperature to maintain technical accuracy, but be mindful that this might reduce the uniqueness of the content.
- For keyword research: High Temperature and High Top P if you want to find more and unique keywords.
- For creative content: A Temperature setting around 0.88 is often optimal, offering a good mix of uniqueness and coherence. Adjust Top P according to the desired level of creativity and randomness.
- For computer programming: Where you want more reliable outputs and usually go with the most popular way of doing something, lower Temperature and Top P parameters make sense.
Prompt engineering strategies
Now that we’ve covered the foundational settings, let’s dive into the second lever we have control over – the prompts.
Prompt engineering is crucial in harnessing the full potential of LLMs. Mastering it means we can pack more instructions into a model, gaining finer control over the final output.
If you’re anything like me, you’ve been frustrated when an AI model just ignores one of your instructions. Hopefully, by understanding a few core ideas, you can reduce this occurrence.
1. The persona and audience pattern: Maximizing instructional efficiency
In AI, much like the human brain, certain words carry a network of associations. Think of the Eiffel Tower – it’s not just a structure; it brings to mind Paris, France, romance, baguettes, etc. Similarly, in AI language models, specific words or phrases can evoke a broad spectrum of related concepts, allowing us to communicate complex ideas in fewer lines.
Implementing the persona pattern
The persona pattern is an ingenious prompt engineering strategy where you assign a “persona” to the AI at the beginning of your prompt. For example, saying, “You are a legal SEO writing expert for consumer readers,” packs a multitude of instructions into one sentence.
Notice at the end of this sentence, I apply what is known as the audience pattern, “for consumer readers.”
Breaking down the persona pattern
Instead of writing out each of these sentences below and using up a large portion of the instruction space, the persona pattern allows us to convey many sentences of instructions in a single sentence.
For example (note this is theoretical), the instruction above may imply the following.
- “Legal SEO writing expert” suggests a multitude of characteristics:
- Precision and accuracy, as expected in legal writing.
- An understanding of SEO principles – keyword optimization, readability, and structuring for search engine algorithms.
- An expert or systematic approach to content creation.
- “For consumer readers” implies:
- The content should be accessible and engaging for the general public.
- It should avoid heavy legal jargon and instead use layman’s terms.
The persona pattern is remarkably efficient, often capturing the essence of multiple sentences into just one.
Getting the persona right is a game-changer. It streamlines your instruction process and provides valuable space for more detailed and specific prompts.
This approach is a smart way to maximize the impact of your prompts while navigating the character limitations inherent in AI models.
2. Zero shot, one shot, and many shot inference methods
Providing examples as part of your prompt engineering is a highly effective technique, especially when seeking outputs in a particular format.
You’re essentially guiding the model by including specific examples, allowing it to recognize and replicate key patterns and characteristics from these examples in its output.
This method ensures that the AI’s responses align closely with your desired format and style, making it an indispensable tool for achieving more targeted and relevant results.
The technique takes on three names.
- Zero shot inference learning: The AI model is given no examples of the desired output.
- One shot inference learning: Involves providing the AI model with a single example of the desired output.
- Many shot inference learning: Provides the AI model with multiple examples of the desired output.
Zero shot inference
- The AI model is prompted to create a title tag without any example. The prompt directly states the task.
- Example prompt: “Create an SEO-optimized title tag for a webpage about the best chef in Cincinnati.”
Here are GPT-4’s responses.

Now let’s see what happens on a smaller model (OpenAI’s Davinci 2).

As you can see, larger models can often perform zero shot prompts, but smaller models struggle.
One shot inference
- Here, you have a single example of an instruction. In this case, we want a small model (OpenAI’s Davinci 2) to classify the sentiment of a review correctly.
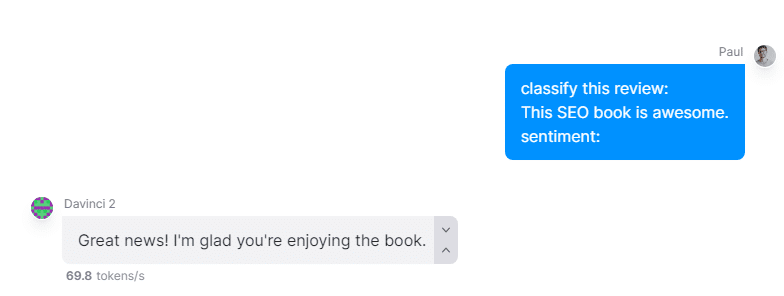

Many shot inference
- Providing several examples helps the AI model understand a range of possible approaches to the task, ideal for complex or nuanced requirements.
- Example prompt: “Create an SEO-optimized title tag for a webpage about the best chef in Cincinnati, like:
- Discover the Best Chefs in Los Angeles – Your Guide to Fine Dining
- Atlanta’s Top Chefs: Who’s Who in the Culinary Scene
- Explore Elite Chefs in Chicago – A Culinary Journey”
Using the zero shot, one shot, and many shot methods, AI models can be effectively guided to produce consistent outputs. These strategies are especially useful in crafting elements like title tags, where precision, relevance, and adherence to SEO best practices are crucial.
By tailoring the number of examples to the model’s capabilities and the task’s complexity, you can optimize your use of AI for content creation.
While developing our web application, we discovered that providing examples is the most impactful prompt engineering technique.
This approach is especially effective even with larger models, as the systems can accurately identify and incorporate the essential patterns needed. This ensures that the generated content aligns closely with your intended goals.
3. ‘Follow all of my rules’ pattern
This strategy is both simple and effective in enhancing the precision of AI-generated responses. Adding a specific instruction line at the beginning of the prompt can significantly improve the likelihood of the AI adhering to all your guidelines.
It’s worth noting that instructions placed at the start of a prompt generally receive more attention from the AI.
So, if you include a directive like “do not skip any steps” or “follow every instruction” right at the outset, it sets a clear expectation for the AI to meticulously follow each part of your prompt.
This technique is particularly useful in scenarios where the sequence and completeness of the steps are crucial, such as in procedural or technical content. Doing so ensures that the AI pays close attention to every detail you’ve outlined, leading to more thorough and accurate outputs.
4. Question refinement pattern
This is a straightforward yet powerful approach to harnessing the AI’s existing knowledge base for better outcomes. You encourage the AI to generate additional, more refined questions. These questions, in turn, guide the AI toward crafting superior outputs that align more closely with your desired results.
This technique prompts the AI to delve deeper and question its initial understanding or response, uncovering more nuanced or specific lines of inquiry.
It’s particularly effective when aiming for a detailed or comprehensive answer, as it pushes the AI to consider aspects it might not have initially addressed.
Here’s an example to illustrate this process in action:
Before: Question refinement strategy

After: Prompt after question refinement strategy
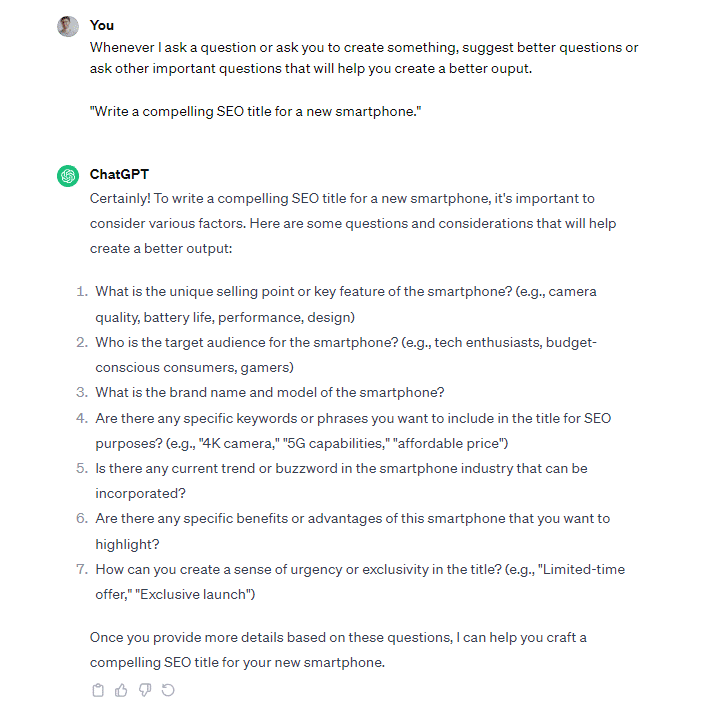
5. ‘Make my prompt more precise’ pattern
The final prompt engineering technique I’d like to introduce is a unique, recursive process where you feed your initial prompts back into GPT.
This allows GPT to act as a collaborator in refining your prompts, helping you to pinpoint more descriptive, precise, and effective language. It’s a reassuring reminder that you’re not alone in the art of prompt crafting.
This method involves a bit of a feedback loop. You start with your original prompt, let GPT process it, and then examine the output to identify areas for enhancement. You can then rephrase or refine your prompt based on these insights and feed it into the system.
This iterative process can lead to more polished and concise instructions, optimizing the effectiveness of your prompts.
Much like the other methods we’ve discussed, this one may require fine-tuning. However, the effort is often rewarded with more streamlined prompts that communicate your intentions clearly and succinctly to the AI, leading to better-aligned and more efficient outputs.

After implementing your refined prompts, you can engage GPT in a meta-analysis by asking it to identify the patterns it followed in generating its responses.

Crafting effective AI prompts for better outputs
The world of AI-assisted content creation doesn’t end here.
Numerous other patterns – like “chain of thought,” “cognitive verifier,” “template,” and “tree of thoughts” – can augment AI to tackle more complex problems and improve question-answering accuracy.
In future articles, we’ll explore these patterns and the intricate practice of splitting prompts between system and user inputs.
via Search Engine Land https://ift.tt/3nActwT
No comments:
Post a Comment