
The prevalence of mass-produced, AI-generated content is making it harder for Google to detect spam.
AI-generated content has also made judging what is quality content difficult for Google.
However, indications are that Google is improving its ability to identify low-quality AI content algorithmically.
Spammy AI content all over the web
You don’t need to be in SEO to know generative AI content has been finding its way into Google search results over the last 12 months.
During that time, Google’s attitude toward AI-created content evolved. The official position moved from “it’s spam and breaks our guidelines” to “our focus is on the quality of content, rather than how content is produced.”
I’m certain Google’s focus-on-quality statement made it into many internal SEO decks pitching an AI-generated content strategy. Undoubtedly, Google’s stance provided just enough breathing room to squeak out management approval at many organizations.
The result: Lots of AI-created, low-quality content flooding the web. And some of it initially made it into the company’s search results.
Invisible junk
The “visible web” is the sliver of the web that search engines choose to index and show in search results.
We know from How Google Search and ranking works, according to Google’s Pandu Nayak, based on Google antitrust trial testimony, that Google “only” maintains an index of ~400 billion documents. Google finds trillions of documents during crawling.
That means Google indexes only 4% of the documents it encounters when crawling the web (400 billion/10 trillion).
Google claims to protect searchers from spam in 99% of query clicks. If that’s even remotely accurate, it’s already eliminating most of the content not worth seeing.
Content is king – and the algorithm is the Emperor’s new clothes
Google claims it’s good at determining the quality of content. But many SEOs and experienced website managers disagree. Most have examples demonstrating inferior content outranking superior content.
Any reputable company investing in content is likely to rank in the top few percent of “good” content on the web. Its competitors are likely to be there, too. Google has already eliminated a ton of lesser candidates for inclusion.
From Google’s point of view, it’s done a fantastic job. 96% of documents didn’t make the index. Some issues are obvious to humans but difficult for a machine to spot.
I’ve seen examples that lead to the conclusion Google is proficient at understanding which pages are “good” and are “bad” from a technical perspective, but relatively ineffective at decerning good content from great content.
Google admitted as much in DOJ anti-trust exhibits. In a 2016 presentation says: “We do not understand documents. We fake it.”

Google relies on user interactions on SERPs to judge content quality
Google has relied on user interactions with SERPs to understand how “good” the contents of a document is. Google explains later the presentation: “Each searcher benefits from the responses of past users… and contributes responses that benefit future users.”
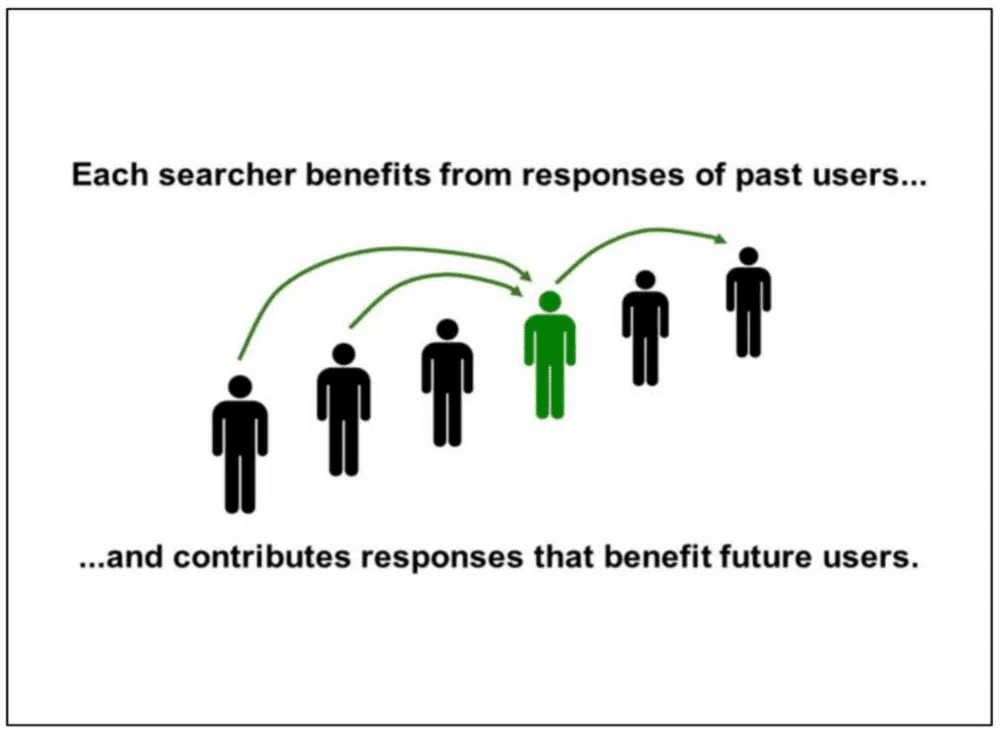
The interaction data Google uses to judge quality has always been a hotly debated topic. I believe Google uses interactions almost entirely from their SERPs, not from websites, to make decisions about content quality. Doing so rules out site-measured metrics like bounce rate.
If you’ve been listening closely to the people who know, Google has been fairly transparent that it uses click data to rank content.
Google engineer Paul Haahr presented “How Google Works: A Google Ranking Engineer’s Story,” at SMX West in 2016. Haahr spoke about Google’s SERPs and how the search engine “looks for changes in click patterns.” He added that this user data is “harder to understand than you might expect.”
Haahr’s comment is further reinforced in the “Ranking for Research” presentation slide, which is part of the DOJ exhibits:

Google’s ability to interpret user data and turn it into something actionable relies on understanding the cause-and-effect relationship between changing variables and their associated outcomes.
The SERPs are the only place Google can use to understand which variables are present. Interactions on websites introduce a vast number of variables beyond Google’s view.
Even if Google could identify and quantify interactions with websites (which would arguably be more difficult than assessing the quality of content), there would be a knock-on effect with the exponential growth of different sets of variables, each requiring minimum traffic thresholds to be met before meaningful conclusions could be made.
Google acknowledges in its documents that “growing UX complexity makes feedback progressively hard to convert into accurate value judgments” when referring to the SERPs.
Brands and the cesspool
Google says the “dialogue” between SERPs and users is the “source of magic” in how it manages to “fake” the understanding of documents.
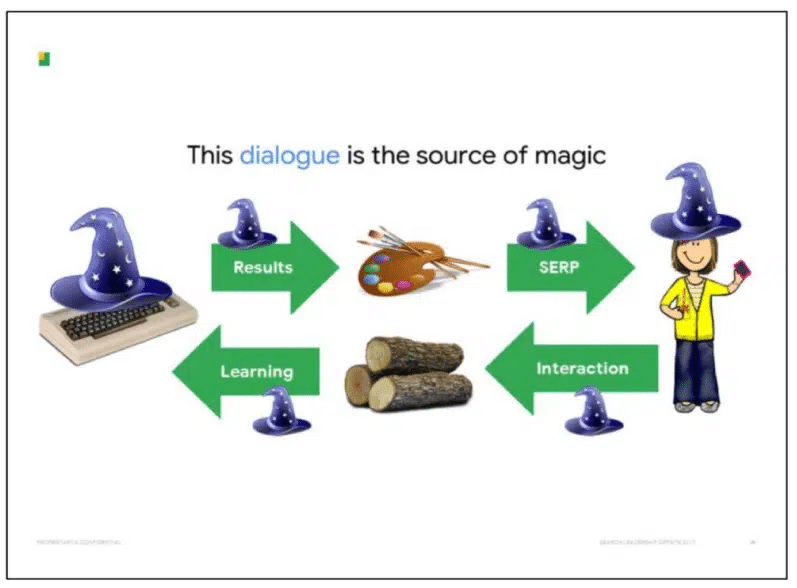
Outside of what we’ve seen in the DOJ exhibits, clues to how Google uses user interaction in rankings are included in its patents.
One that is particularly interesting to me is the “Site quality score,” which (to grossly oversimplify) looks at relationships such as:
- When searchers include brand/navigational terms in their query or when websites include them in their anchors. For instance, a search query or link anchor for “seo news searchengineland” rather than “seo news.”
- When users appear to be selecting a specific result within the SERP.
These signals may indicate a site is an exceptionally relevant response to the query. This method of judging quality aligns with Google’s Eric Schmidt saying, “brands are the solution.”
This makes sense in light of studies that show users have a strong bias toward brands.
For instance, when asked to perform a research task such as shopping for a party dress or searching for a cruise holiday, 82% of participants selected a brand they were already familiar with, regardless of where it ranked on the SERP, according to a Red C survey.
Brands and the recall they cause are expensive to create. It makes sense that Google would rely on them in ranking search results.
What does Google consider AI spam?
Google published guidance on AI-created content this year, which refers to its Spam Policies the define define content that is “intended to manipulate search results.”
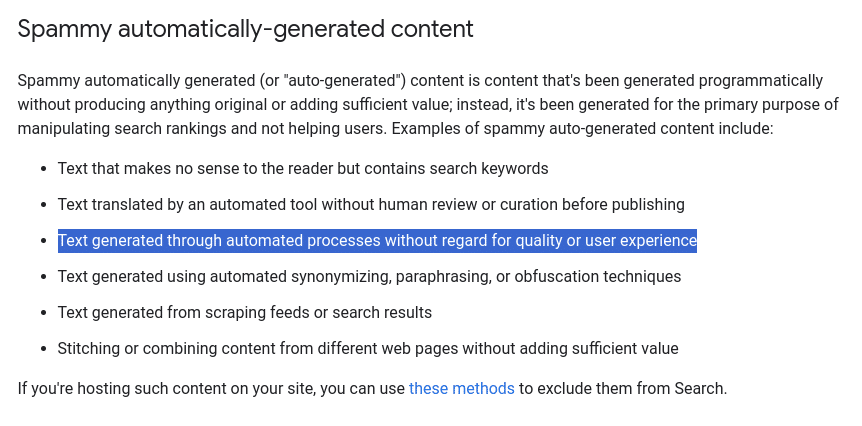
Spam is “Text generated through automated processes without regard for quality or user experience,” according to Google’s definition. I interpret this as anyone using AI systems to produce content without a human QA process.
Arguably, there could be cases where a generative-AI system is trained on proprietary or private data. It could be configured to have more deterministic output to reduce hallucinations and errors. You could argue this is QA before the fact. It’s likely to be a rarely-used tactic.
Everything else I’ll call “spam.”
Generating this kind of spam used to be reserved for those with the technical ability to scrape data, build databases for madLibbing or use PHP to generate text with Markov chains.
ChatGPT has made spam accessible to the masses with a few prompts and an easy API and OpenAI’s ill-enforced Publication Policy, which states:
“The role of AI in formulating the content is clearly disclosed in a way that no reader could possibly miss, and that a typical reader would find sufficiently easy to understand.”

The volume of AI-generated content being published on the web is enormous. A Google Search for “regenerate response -chatgpt -results” displays tens of thousands of pages with AI content generated “manually” (i.e., without using an API).
In many cases QA has been so poor “authors” left in the “regenerate response” from the older versions of ChatGPT during their copy and paste.
Patterns of AI content spam
When GPT-3 hit, I wanted to see how Google would react to unedited AI-generated content, so I set up my first test website.
This is what I did:
- Bought a brand new domain and set up a basic WordPress install.
- Scraped the top 10,000 games that were selling on Steam.
- Fed these games into the AlsoAsked API to get the questions being asked by them.
- Used GPT-3 to generate answers to these questions.
- Generate FAQPage schema for each question and answer.
- Scraped the URL for a YouTube video about the game to embed on the page.
- Use the WordPress API to create a page for each game.
There were no ads or other monetization features on the site.
The whole process took a few hours, and I had a new 10,000-page website with some Q&A content about popular video games.
Both Bing and Google ate up the content and, over a period of three months, indexed most pages. At its peak, Google delivered over 100 clicks per day, and Bing even more.

Results of the test:
- After about 4 months, Google decided not to rank some content, resulting in a 25% hit in traffic.
- A month later, Google stopped sending traffic.
- Bing kept sending traffic for the entire period.
The most interesting thing? Google did not appear to have taken manual action. There was no message in Google Search Console, and the two-step reduction in traffic made me skeptical that there had been any manual intervention.
I’ve seen this pattern repeatedly with pure AI content:
- Google indexes the site.
- Traffic is delivered quickly with steady gains week on week.
- Traffic then peaks, which is followed by a rapid decline.
Another example is the case of Casual.ai. In this “SEO heist,” a competitor’s sitemap was scraped and 1,800+ articles were generated with AI. Traffic followed the same pattern, climbing several months before stalling, then a dip of around 25% followed by a crash that eliminated nearly all traffic.
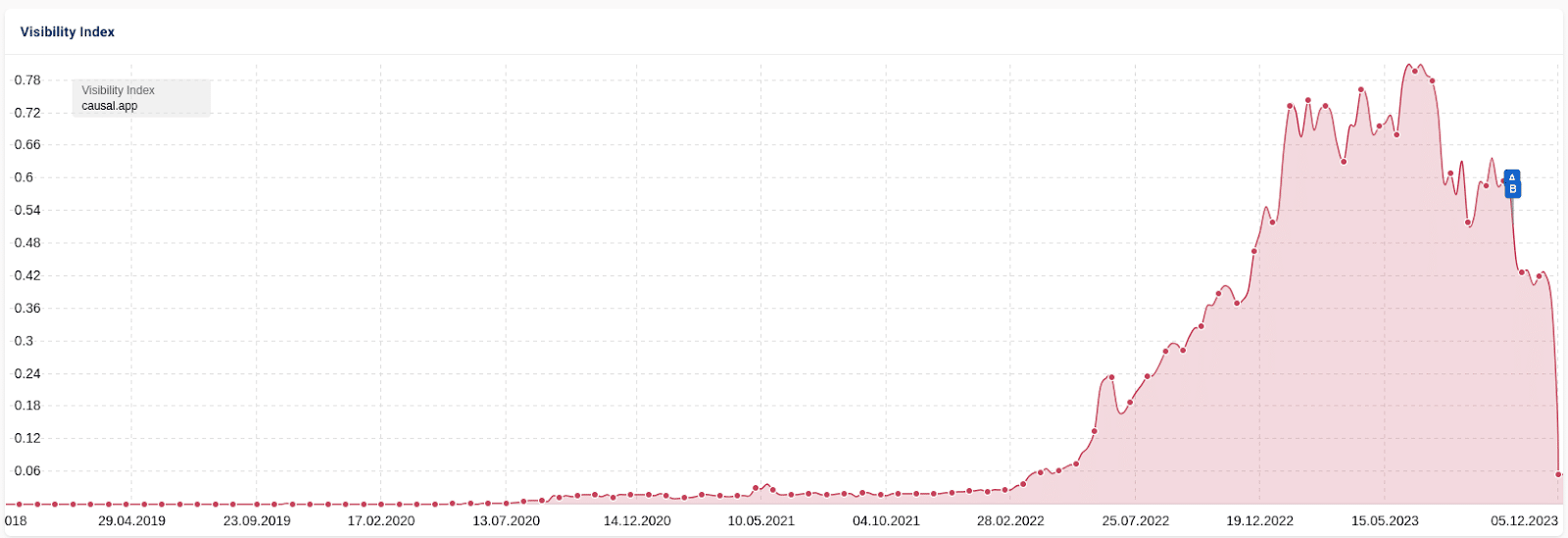
There is some discussion in the SEO community about whether this drop was a manual intervention because of all the press coverage it got. I believe the algorithm was at work.
A similar and perhaps more interesting case study involved LinkedIn’s “collaborative” AI articles. These AI-generated articles created by LinkedIn invited users to “collaborate” with fact-checking, corrections and additions. It rewarded “top contributors” with a LinkedIn badge for their efforts.
As with the other cases, traffic rose and then dropped. However, LinkedIn maintained some traffic.
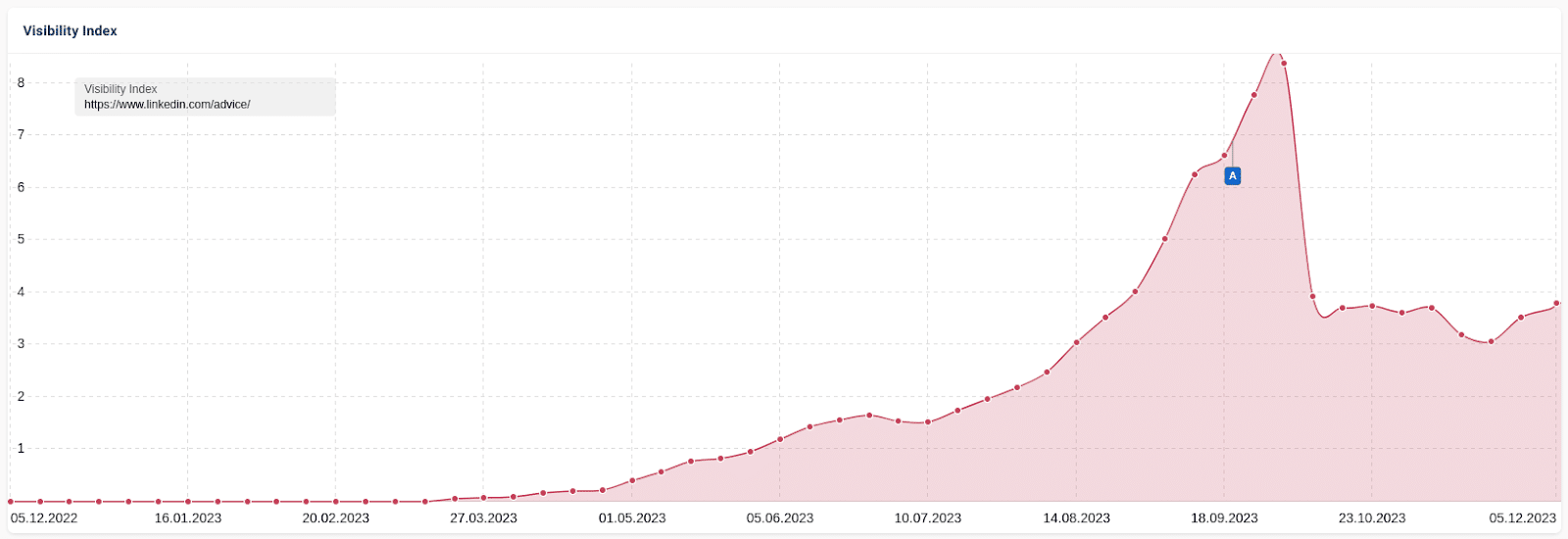
This data indicates that traffic fluctuations result from an algorithm rather than a manual action.
Once edited by a human, some LinkedIn collaborative articles apparently met the definition of useful content. Others were not, in Google’s estimation.
Maybe Google’s got it right in this instance.
If it’s spam, why does it rank at all?
From everything I have seen, ranking is a multi-stage process for Google. Time, expense, and limits on data access prevent the implementation of more complex systems.
While the assessment of documents never stops, I believe there is a lag before Google’s systems detect low-quality content. That’s why you see the pattern repeat: content passes an initial “sniff test,” only to be identified later.
Let’s take a look at some of the evidence for this claim. Earlier in this article, we skimmed over Google’s “Site Quality” patent and how they leverage user interaction data to generate this score for ranking.
When a site is brand new, users haven’t interacted with the content on the SERP. Google can’t access the quality of the content.
Well, another patent for Predicting Site Quality covers this situation.
Again, to grossly oversimplify, a quality score for new sites is predicted by first obtaining a relative frequency measure for each of a variety of phrases found on the new site.
These measures are then mapped using a previously generated phrase model built from quality scores established from previously scored sites.

If Google were still using this (which I believe they are, at least a small way), it would mean that many new websites are ranked on a “first guess” basis with a quality metric included in the algorithm. Later, the ranking is refined based on user interaction data.
I have observed, and many colleagues agree, that Google sometimes elevates sites in ranking for what appears to be a “test period.”
Our theory at the time was there was a measurement going on to see if user interaction matched Google’s predictions. If not, traffic fell as quickly as it rose. If it performed well, it continued to enjoy a healthy position on the SERP.
Many of Google’s patents have references to “implicit user feedback,” including this very candid statement:
“A ranking sub-system can include a rank modifier engine that uses implicit user feedback to cause re-ranking of search results in order to improve the final ranking presented to a user.”
AJ Kohn wrote about this kind of data in detail back in 2015.
It is worth noting that this is an old patent and one of many. Since this patent was published, Google has developed many new solutions, such as:
- RankBrain, which has specifically been cited to handle “new” queries for Google.
- SpamBrain, one of Google’s main tools for combatting webspam.
Google: Mind the gap
I don’t think anyone outside of those with first-hand engineering knowledge at Google knows exactly how much user/SERP interaction data would be applied to individual sites rather than the overall SERP.
Still, we know that modern systems such as RankBrain are at least partly trained on user click data.
One thing also piqued my interest in AJ Kohn’s analysis of the DOJ testimony on these new systems. He writes:
“There are a number of references to moving a set of documents from the ‘green ring to the ‘blue ring.’ These all refer to a document that I have not yet been able to locate. However, based on the testimony it seems to visualize the way Google culls results from a large set to a smaller set where they can then apply further ranking factors.”
This supports my sniff-test theory. If a website passes, it gets moved to a different “ring” for more computationally or time-intensive processing to improve accuracy.
I believe this to be the current situation:
- Google’s current ranking systems can’t keep pace with AI-generated content creation and publication.
- As gen-AI systems produce grammatically correct and mostly “sensible” content, they pass Google’s “sniff tests” and will rank until further analysis is complete.
Herein lies the problem: the speed at which this content is being created with generative AI means there is an unending queue of sites waiting for Google’s initial evaluation.
An HCU hop to UGC to beat the GPT?
I believe Google knows this is one major challenge they face. If I can indulge in some wild speculation, it’s possible that recent Google updates, such as the helpful content update (HCU), have been applied to compensate for this weakness.
It’s no secret the HCU and “hidden gems” systems benefited user-generated content (UGC) sites such as Reddit.
Reddit was already one of the most visited websites. Recent Google changes yielded more than double its search visibility, at the expense of other websites.
My conspiracy theory is that UGC sites, with a few notable exceptions, are some of the least likely places to find mass-produced AI, as much content is moderated.
While they may not be “perfect” search results, the overall satisfaction of trawling through some raw UGC may be higher than Google consistently ranking whatever ChatGPT last vomited onto the web.
The focus on UGC may be a temporary fix to boost quality; Google can’t tackle AI spam fast enough.
What does Google’s long-term plan look like for AI spam?
Much of the testimony about Google in the DOJ trial came from Eric Lehman, a former 17-year employee who worked there as a software engineer on search quality and ranking.
One recurring theme was Lehman’s claims that Google’s machine learning systems, BERT and MUM, are becoming more important than user data. They are so powerful that it is likely Google will rely more on them than user data in the future.
With slices of user interaction data, search engines have an excellent proxy for which they can make decisions. The limitation is collecting enough data fast enough to keep up with changes, which is why some systems employ other methods.
Suppose Google can build their models using breakthroughs such as BERT to massively improve the accuracy of their first content parsing. In that case, they may be able to close the gap and drastically reduce the time it takes to identify and de-rank spam.
This problem exists and is exploitable. The pressure on Google to address its shortcomings increases as more people search for low-effort, high-results opportunities.
Ironically, when a system becomes effective in combatting a specific type of spam at scale, the system can make itself almost redundant as the opportunity and motivation to take part is diminished.
Fingers crossed.
via Search Engine Land https://ift.tt/xU6Yju3
No comments:
Post a Comment